Introduction to xarray, InferenceData, and netCDF for ArviZ#
While ArviZ supports plotting from familiar data types, such as dictionaries and NumPy arrays, there are a couple of data structures central to ArviZ that are useful to know when using the library.
They are
Why more than one data structure?#
Bayesian inference generates numerous datasets that represent different aspects of the model. For example, in a single analysis, a Bayesian practitioner could end up with any of the following data.
Prior Distribution for N number of variables
Posterior Distribution for N number of variables
Prior Predictive Distribution
Posterior Predictive Distribution
Trace data for each of the above
Sample statistics for each inference run
Any other array like data source
For more detail, see the InferenceData structure specification here.
Why not Pandas Dataframes or NumPy Arrays?#
Data from probabilistic programming is naturally high dimensional. To add to the complexity ArviZ must handle the data generated from multiple Bayesian modeling libraries, such as PyMC3 and PyStan. This application is handled by the xarray package quite well. The xarray package lets users manage high dimensional data with human readable dimensions and coordinates quite easily.
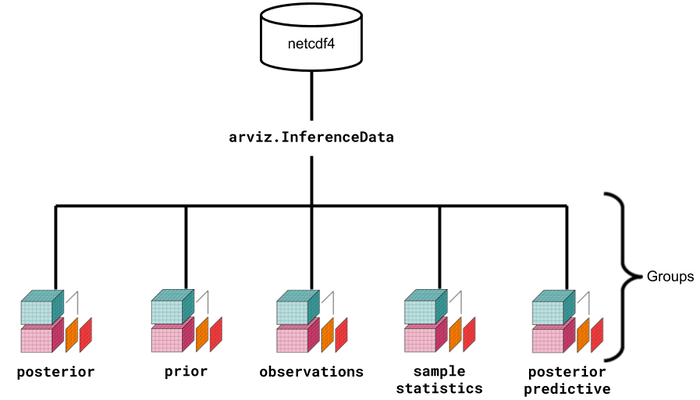
Above is a visual representation of the data structures and their relationships. Although it seems more complex at a glance, the ArviZ devs believe that the usage of xarray, InferenceData, and netCDF will simplify the handling, referencing, and serialization of data generated during Bayesian analysis.
An introduction to each#
To help get familiar with each, ArviZ includes some toy datasets. You can check the different ways to start an InferenceData here. For illustration purposes, here we have shown only one example provided by the library. To start an az.InferenceData, sample can be loaded from disk.
# Load the centered eight schools model
import arviz as az
data = az.load_arviz_data("centered_eight")
data
-
<xarray.Dataset> Dimensions: (chain: 4, draw: 500, school: 8) Coordinates: * chain (chain) int64 0 1 2 3 * draw (draw) int64 0 1 2 3 4 5 6 7 8 ... 492 493 494 495 496 497 498 499 * school (school) object 'Choate' 'Deerfield' ... "St. Paul's" 'Mt. Hermon' Data variables: mu (chain, draw) float64 -3.477 -2.456 -2.826 ... 4.597 5.899 0.1614 theta (chain, draw, school) float64 1.669 -8.537 -2.623 ... 10.59 4.523 tau (chain, draw) float64 3.73 2.075 3.703 4.146 ... 8.346 7.711 5.407 Attributes: created_at: 2019-06-21T17:36:34.398087 inference_library: pymc3 inference_library_version: 3.7 -
<xarray.Dataset> Dimensions: (chain: 4, draw: 500, school: 8) Coordinates: * chain (chain) int64 0 1 2 3 * draw (draw) int64 0 1 2 3 4 5 6 7 8 ... 492 493 494 495 496 497 498 499 * school (school) object 'Choate' 'Deerfield' ... "St. Paul's" 'Mt. Hermon' Data variables: obs (chain, draw, school) float64 7.85 -19.03 -22.5 ... 4.698 -15.07 Attributes: created_at: 2019-06-21T17:36:34.489022 inference_library: pymc3 inference_library_version: 3.7 -
<xarray.Dataset> Dimensions: (chain: 4, draw: 500, school: 8) Coordinates: * chain (chain) int64 0 1 2 3 * draw (draw) int64 0 1 2 3 4 5 6 ... 493 494 495 496 497 498 499 * school (school) object 'Choate' 'Deerfield' ... 'Mt. Hermon' Data variables: tune (chain, draw) bool True False False ... False False False depth (chain, draw) int64 5 3 3 4 5 5 4 4 5 ... 4 4 4 5 5 5 5 5 tree_size (chain, draw) float64 31.0 7.0 7.0 15.0 ... 31.0 31.0 31.0 lp (chain, draw) float64 -59.05 -56.19 ... -63.62 -58.35 energy_error (chain, draw) float64 0.07387 -0.1841 ... -0.087 -0.003652 step_size_bar (chain, draw) float64 0.2417 0.2417 ... 0.1502 0.1502 max_energy_error (chain, draw) float64 0.131 -0.2067 ... -0.101 -0.1757 energy (chain, draw) float64 60.76 62.76 64.4 ... 67.77 67.21 mean_tree_accept (chain, draw) float64 0.9506 0.9906 ... 0.9875 0.9967 step_size (chain, draw) float64 0.1275 0.1275 ... 0.1064 0.1064 diverging (chain, draw) bool False False False ... False False False log_likelihood (chain, draw, school) float64 -5.168 -4.589 ... -3.896 Attributes: created_at: 2019-06-21T17:36:34.485802 inference_library: pymc3 inference_library_version: 3.7 -
<xarray.Dataset> Dimensions: (chain: 1, draw: 500, school: 8) Coordinates: * chain (chain) int64 0 * draw (draw) int64 0 1 2 3 4 5 6 7 ... 492 493 494 495 496 497 498 499 * school (school) object 'Choate' 'Deerfield' ... 'Mt. Hermon' Data variables: tau (chain, draw) float64 6.561 1.016 68.91 ... 1.56 5.949 0.7631 tau_log__ (chain, draw) float64 1.881 0.01593 4.233 ... 1.783 -0.2704 mu (chain, draw) float64 5.293 0.8137 0.7122 ... -1.658 -3.273 theta (chain, draw, school) float64 2.357 7.371 7.251 ... -3.775 -3.555 obs (chain, draw, school) float64 -3.54 6.769 19.68 ... -21.16 -6.071 Attributes: created_at: 2019-06-21T17:36:34.490387 inference_library: pymc3 inference_library_version: 3.7 -
<xarray.Dataset> Dimensions: (school: 8) Coordinates: * school (school) object 'Choate' 'Deerfield' ... "St. Paul's" 'Mt. Hermon' Data variables: obs (school) float64 28.0 8.0 -3.0 7.0 -1.0 1.0 18.0 12.0 Attributes: created_at: 2019-06-21T17:36:34.491909 inference_library: pymc3 inference_library_version: 3.7
In this case the az.InferenceData object contains both a posterior predictive distribution and the observed data, among other datasets. Each group in InferenceData is both an attribute on InferenceData and itself a xarray.Dataset object.
# Get the posterior dataset
posterior = data.posterior
posterior
<xarray.Dataset>
Dimensions: (chain: 4, draw: 500, school: 8)
Coordinates:
* chain (chain) int64 0 1 2 3
* draw (draw) int64 0 1 2 3 4 5 6 7 8 ... 492 493 494 495 496 497 498 499
* school (school) object 'Choate' 'Deerfield' ... "St. Paul's" 'Mt. Hermon'
Data variables:
mu (chain, draw) float64 -3.477 -2.456 -2.826 ... 4.597 5.899 0.1614
theta (chain, draw, school) float64 1.669 -8.537 -2.623 ... 10.59 4.523
tau (chain, draw) float64 3.73 2.075 3.703 4.146 ... 8.346 7.711 5.407
Attributes:
created_at: 2019-06-21T17:36:34.398087
inference_library: pymc3
inference_library_version: 3.7In our eight schools model example, the posterior trace consists of 3 variables and approximately over 4 chains. In addition, it is a hierarchical model where values for the variable theta are associated with a particular school.
According to the xarray’s terminology:
Data variables are the actual values generated from the MCMC draws
Dimensions are the axes that refer to the data variables
Coordinates are pointers to specific slices or points in the
xarray.Dataset
Observed data from the eight schools model can be accessed through the same method.
# Get the observed xarray
observed_data = data.observed_data
observed_data
<xarray.Dataset>
Dimensions: (school: 8)
Coordinates:
* school (school) object 'Choate' 'Deerfield' ... "St. Paul's" 'Mt. Hermon'
Data variables:
obs (school) float64 28.0 8.0 -3.0 7.0 -1.0 1.0 18.0 12.0
Attributes:
created_at: 2019-06-21T17:36:34.491909
inference_library: pymc3
inference_library_version: 3.7It should be noted that the observed dataset contains only 8 data variables. Moreover, it doesn’t have a chain and draw dimension or coordinates unlike posterior. This difference in sizes is the motivating reason behind InferenceData. Rather than force multiple different sized arrays into one array, or have users manage multiple objects corresponding to different datasets, it is easier to hold references to each xarray.Dataset in an InferenceData object.
NetCDF#
NetCDF is a standard for referencing array oriented files. In other words, while xarray.Datasets, and by extension InferenceData, are convenient for accessing arrays in Python memory, netCDF provides a convenient mechanism for persistence of model data on disk. In fact, the netCDF dataset was the inspiration for InferenceData as netCDF4 supports the concept of groups. InferenceData merely wraps xarray.Dataset with the same functionality.
Most users will not have to concern themselves with the netCDF standard but for completeness it is good to make its usage transparent. It is also worth noting that the netCDF4 file standard is interoperable with HDF5 which may be familiar from other contexts.
Earlier in this tutorial InferenceData was loaded from a netCDF file
data = az.load_arviz_data("centered_eight")
Similarly, the InferenceData objects can be persisted to disk in the netCDF format
data.to_netcdf("eight_schools_model.nc")
'eight_schools_model.nc'
Additional Reading#
Additional documentation and tutorials exist for xarray and netCDF4. Check the following links:
InferenceData#
Working with InferenceData: Tutorial covering the most common operations with
InferenceDataobjectsCreating InferenceData: Cookbook with examples of generating InferenceData objects from multiple sources, both external inference libraries like
InferenceData API reference: description of all available
InferenceDatamethods, grouped by topic
xarray#
For getting to know xarray, check xarray documentation
Feel free to watch the Q/A session about xarray at xarray lightning talk at SciPy 2015
NetCDF#
Get to know the introduction of netCDF at the official website of NetCDF documentation
Netcdf4-python library is a used to read/write netCDF files in both netCDF4 and netCDF3 format. Learn more about it by visitng its API documentation at NetCDF4 API documentation
xarray provides direct serialization and IO to netCDF format. Learn how to read/write netCDF files directly as xarray objects at NetCDF usage in xarray
Check how to read/write netCDF4 files with HDF5 and vice versa at NetCDF interoperability with HDF5